Will mobile phones transform the lives of the world’s poor? Pick up a
recent issue of The Economist and it seems like a
fait accompli. With over 90% of the developing world now receiving coverage, and the advent of innovative applications like telemedicine, ICT-based agricultural extensions and Mobile Money (a form of phone-based electronic currency akin to PayPal), mobile phones have the potential to provide a game-changing platform for international development.
Yet for all the hype, we know little about whether and how mobile phones will have a lasting impact. Countries with high rates of mobile phone penetration tend to be better off in a number of ways, but figuring out what caused what is no simple matter.
This is where “Big Data” can make a difference.
In a
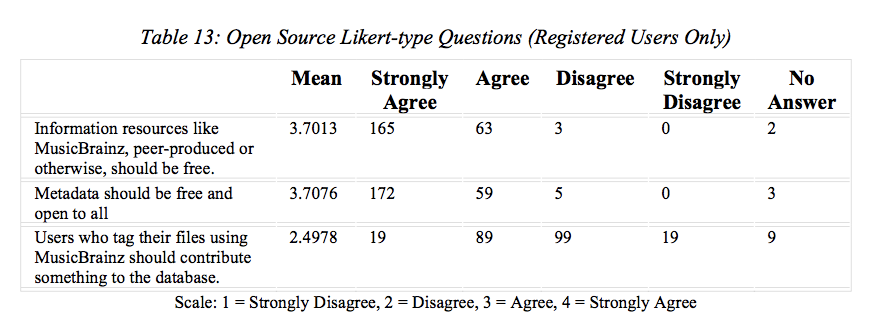
recent paper I wrote with Nathan Eagle and Marcel Fafchamps, we found patterns in ten terabytes of Rwandan mobile phone use data that help illuminate the role of mobile phones in Rwanda’s economy. Focusing on the micro-level behavior of individuals captured in the data enabled us to avoid many of the common pitfalls of making causal inferences based on trends in macroeconomic indicators.
We first noticed that after major shocks like earthquakes and natural disasters, individuals in Rwanda sent a significant volume of “Mobile Money” to the people affected. In the below video, you can see how dramatically the
Lake Kivu earthquake affected patterns of mobile phone traffic in the country:
Using econometric models, we quantified this response. Following the 2008 earthquake, a total of $85 was sent to the earthquake victims over the mobile phone network. Because of increased adoption over the past few years, we estimate that roughly $30,000 would be sent in response to an earthquake today. In a small country where most people earn only a few dollars a day, this is a sizable amount of money.
Perhaps more importantly, when we analyze the dynamics of the social network captured in the billions of phone calls and transfers, we find that the pattern of activity is most consistent with a model of
risk sharing—i.e., John helps Jane when Jane is in trouble because he expects Jane to reciprocate in John’s time of need. In places like Rwanda, where banks are rare and people tend to have limiting savings, such risk sharing makes a major difference in insuring individuals against income volatility and protecting against the “poverty traps” that prevent people from moving out of poverty.
This is good news for advocates of expanding of mobile networks and services in developing countries. To the extent that Mobile Money facilitates risk sharing, results indicate that the technology can be a positive force for economic development.
However, not everything is positive. We observe that it is chiefly wealthy mobile phone owners, and the ones with the strongest social networks, who receive the lion’s share of the risk-sharing transfers. Taken together, these results indicate that the mobile network can improve the welfare of some but, absent intervention, the benefits may not reach those with the greatest need.
Josh Blumenstock is a PhD candidate at UC Berkeley’s School of Information.